

EU AI Act: Turning evidence obligations into a release artefact
A practical, engineer-friendly guide to EU AI Act evidence—technical documentation, record-keeping, and post-market monitoring—and how Assurance Packs keep it current across releases.
- regulation
- governance
- assurance
- monitoring
Disclaimer (read first): This article is informational only and not legal advice. The EU AI Act is a legal text; how it applies depends on your role (provider/deployer/importer/distributor), your system’s classification (high-risk, transparency-risk, prohibited, etc.), and your deployment context. Always consult qualified legal counsel for compliance decisions.
Understanding the EU AI Act: what it is and why it matters
The EU AI Act (formally Regulation (EU) 2024/1689) is Europe’s landmark AI regulation (official text). It uses a risk-based framework: obligations scale with the potential impact of the system, from prohibited practices (Article 5) to high-risk systems (Article 6, Annex I, Annex III) and transparency obligations (Article 50).
In practice, teams often think in four buckets:
- Prohibited practices — not allowed to deploy (see Article 5).
- High-risk systems — allowed, but subject to requirements such as technical documentation (Article 11 and Annex IV), record-keeping (Article 12), and post-market monitoring (Article 72).
- Transparency obligations — certain systems must disclose AI use or label synthetic content (see Article 50).
- Everything else — many AI systems fall outside the high-risk obligations, but customers, auditors, and procurement may still expect clear evidence of intent, evaluation, and monitoring.
Critically, the Act doesn’t just set one-time rules; it imposes ongoing obligations across the AI system’s lifecycle. This includes maintaining up-to-date technical documentation, keeping detailed logs, and actively monitoring post-market performance for issues. These evidence obligations are where many teams struggle – and that’s exactly the gap this post will address.
Why this post exists: “evidence” is the new delivery artefact
Most teams don’t fail governance because they lack intent. They fail because evidence is not treated like a first-class release artefact.
- Docs live in a wiki.
- Metrics live in an experiment tracker.
- Logs live in a monitoring tool.
- Risk notes live in someone’s head (or a one-off PDF).

Then procurement, auditors, or regulators ask: “Show me what changed between v1.3 and v1.4, and why that change is safe.”
That’s the gap the EU AI Act amplifies: it pushes organizations to maintain technical documentation, logs, and post-market monitoring as ongoing lifecycle obligations, not a one-time “paperwork sprint.” In other words, if you can’t produce up-to-date evidence for how your AI system was built, how it operates, and how it’s being overseen, you won’t meet the bar.
The Ormedian take is simple:
Ship an Assurance Pack for every release.
A versioned, shareable evidence bundle that stays coupled to the system version you actually deployed.
This article explains:
- the EU AI Act timeline (what kicks in when),
- the evidence obligations that matter most for engineering teams, and
- how to operationalize them as a release artefact (Assurance Packs) so evidence stays current.
EU AI Act in 5 minutes: the phased timeline that matters
The EU AI Act entered into force in 2024 and applies progressively over the next few years. The Commission’s Service Desk timeline is the simplest way to track what takes effect when:
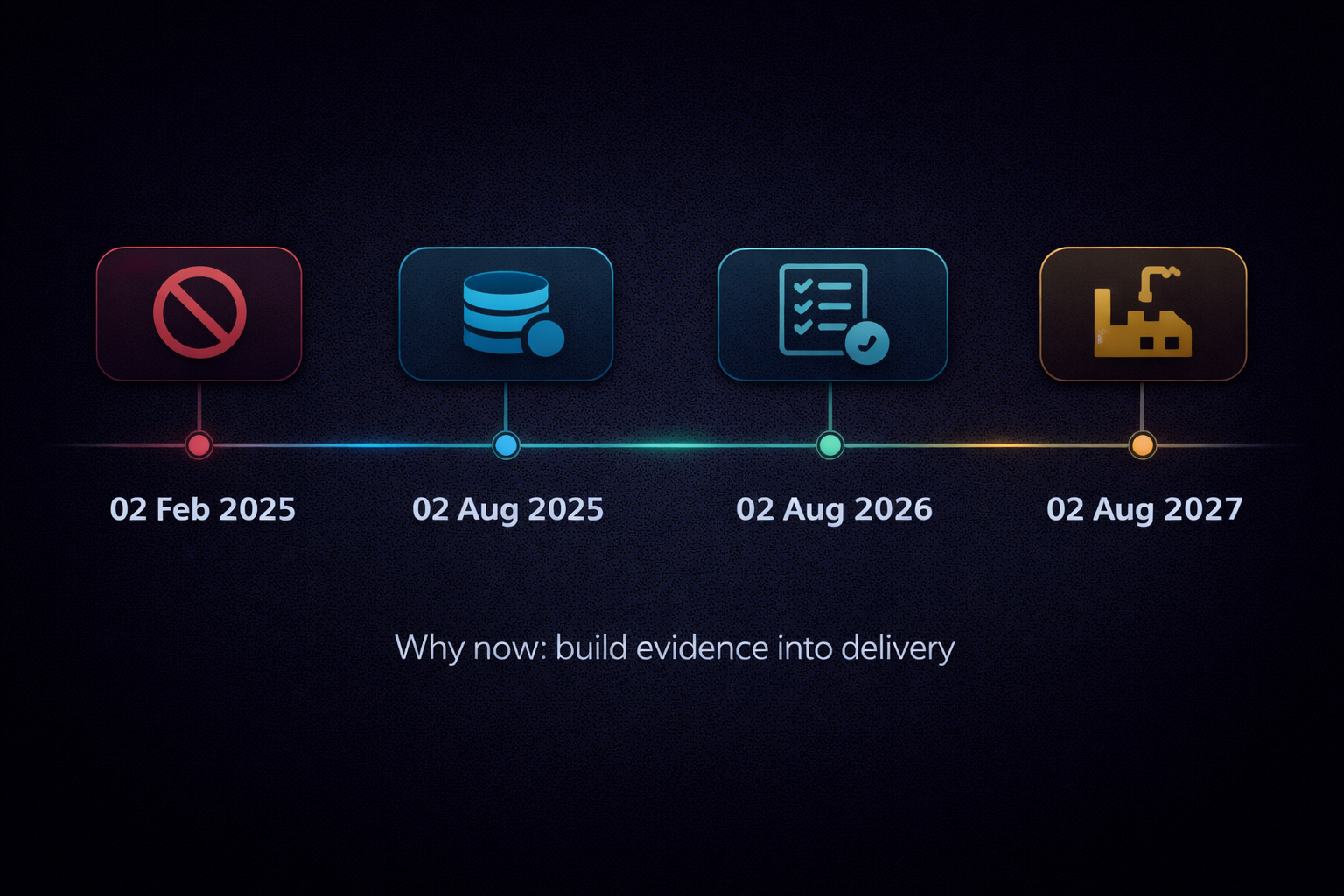
- 02 Feb 2025 — General provisions start to apply, including definitions (Article 3), AI literacy (Article 4), and prohibited practices (Article 5) (timeline).
- 02 Aug 2025 — Governance structures and general-purpose AI (GPAI) obligations begin to apply (timeline).
- 02 Aug 2026 — The majority of rules apply; this is “day one” of enforcement for many high-risk requirements (notably systems in Annex III) and transparency obligations (Article 50). Member States should have at least one AI regulatory sandbox operational by this date (timeline).
- 02 Aug 2027 — High-risk obligations extend to certain AI systems embedded in regulated products (Annex I) (timeline).
If you remember nothing else: you don’t have “years” to think about evidence. The discipline needs to be built into delivery now. By August 2026, any high-risk AI system you offer in the EU must have compliance evidence ready on demand – and if you’re selling into regulated industries or public sector, the expectation (even before 2026) is to show this mindset today.
First decision: are you even in scope, and at what risk level?
The Act is risk-based
As noted, the AI Act is risk-based: it defines prohibited practices (Article 5), high-risk systems (Article 6 with lists in Annex I and Annex III), transparency obligations (Article 50), and the core definitions you’ll need to interpret all of that (Article 3).
- Prohibited AI – Don’t go there. These are use-cases banned outright (e.g. exploiting vulnerabilities of specific groups, social scoring, certain types of biometric surveillance) (Article 5). No compliance regime exists because you’re not allowed to deploy them at all.
- High-risk AI – This is the most consequential category for compliance. High-risk systems are the only ones subject to the full brunt of the AI Act’s requirements (technical documentation, logging, monitoring, human oversight, etc.).
- Transparency-risk AI – These include systems like conversational AI or deepfake generators that aren’t high-risk but require user disclosures or other transparency measures (Article 50).
- Minimal-risk AI – Everything else. No specific obligations (beyond existing laws), though voluntary best practices are encouraged.
High-risk classification (the engineering trigger)
So what makes an AI system “high-risk”? The classification rules are in Article 6. In simple terms, an AI system is high-risk if either:
- it’s intended to be used as a safety component of a regulated product (or is itself such a product) listed in Annex I (think: brakes controlled by AI, AI in medical devices); or
- it’s one of the use-cases listed in Annex III (areas like education, employment, critical infrastructure, law enforcement, etc.).
There is nuance: some Annex III systems can fall out of scope if they do not pose a significant risk — but those exceptions are narrow and must be justified and documented (see Article 6).
In short, “high-risk” is the default if your use-case is in Annex III. The burden is on you to prove otherwise. When in doubt, assume high-risk and prepare the evidence accordingly.
“AI model” vs “AI system”
Another scope question: many teams use pretrained models or APIs (think GPT-4, vision APIs). Are you a provider of an AI system, or just a user of an AI model? The definitions you need (including “AI system” and related actor roles) are in Article 3. In practice, a model becomes part of an AI system when you add the surrounding components (data inputs, a user interface, decision logic, and operating context) that define its purpose.
Why does this matter? Because obligations differ depending on whether you are:
- a provider placing an AI system on the EU market or putting it into service,
- a deployer using an AI system internally,
- a provider of a general-purpose AI model (e.g. offering a foundation model), or
- part of the distribution chain (importer, distributor).
For example, if you fine-tune a large language model and offer it as a SaaS product for hiring, you’re the provider of a high-risk AI system (employment = Annex III). If you just consume someone else’s API for internal use, you’re a deployer and have a lighter (but not zero) load. As an engineering leader, identify which role fits you now (see Article 3): it determines how you approach evidence and ongoing obligations.
The “evidence triangle”: what the EU AI Act forces you to produce and maintain
Strip away the legalese and you can boil the Act’s compliance down to three continuous evidence streams (for high-risk systems):

- Technical documentation – Required under Article 11, with the detailed contents in Annex IV. It covers what the system is, intended purpose, how it works, how it was validated, and how it evolves between versions.
- Record-keeping (logging) – Automatic logs that capture the system’s operation and outcomes, sufficient to trace issues or decisions (see Article 12). Essentially, an audit trail for the AI’s functioning.
- Post-market monitoring – A proactive plan and system for monitoring the AI after deployment, to detect problems or degradation and take action (see Article 72). This includes reporting serious incidents under Article 73.
These three obligations reinforce each other. Think of it as an evidence triangle: documentation, logging, and monitoring. If one side is weak, the whole assurance collapses. For example, logs without documentation are just data with no context; documentation without monitoring becomes stale fiction; monitoring without logs means you can’t investigate incidents.
The minimum evidence set (practical mapping)
If you want a practical way to think about evidence, treat these as three versioned outputs that ship with every release:

- Article 11 + Annex IV → a technical documentation bundle for the specific version you shipped.
- Article 12 → logging and record-keeping capability (structured event logs, retained as required).
- Article 72 → a post-market monitoring plan plus a running monitoring process/system.
1) Technical documentation: Annex IV is the spine
For high-risk systems, Annex IV of the Act sets out what technical documentation must include. In short, it’s a comprehensive “tech spec + compliance report” for your AI system. The Commission’s service desk provides a view of Annex IV and a link to the official text:
- Annex IV (Service Desk summary) – a readable breakdown of the requirements.
- Official act text (EUR-Lex) – the legal text, if you enjoy that.
A practical (non-exhaustive) reading of Annex IV looks like this:
- Intended purpose + versioning – What is the system meant to do (and not do), who built it, and the exact version (including how it relates to previous versions).
- System architecture + integration – How the AI model and other components work together (e.g. data pipeline, UI, APIs) and the context it operates in.
- Data – The characteristics and provenance of training and test data: where it came from, how it was collected or annotated, any biases or limitations.
- Development process – How you built the model (did you fine-tune a pretrained model? use AutoML? what steps in training?).
- Model performance and limits – The AI’s capabilities and accuracy (overall and on specific relevant groups), and its known limitations or foreseeable unintended outcomes.
- Validation and testing – How you validated the model: which metrics, test datasets, robustness checks, and the results (including test logs and reports).
- Risk management – The known risks (e.g. failure modes, potential for bias, cybersecurity vulnerabilities) and the measures in place to mitigate them (which ties to the required risk management system from Article 9).
- Changes and versions – If you update the AI, what changed and why, and evidence the new version still meets the documented intent, tests, and controls.
- Post-market plan – Annex IV expects the post-market monitoring plan (from Article 72) to be part of your technical documentation bundle for each version.
Key point: Annex IV makes “versioned evidence” unavoidable. It explicitly ties documentation to the AI system’s version and lifecycle. This is why treating evidence as a continuous release artefact (not a one-time PDF) is the sane way forward. Every time you ship a new model or update, the documentation needs to be updated and re-issued.
2) Record-keeping: logs as a compliance primitive (Article 12)
High-risk AI systems must “technically allow for the automatic recording of events (logs) over the lifetime of the system” (see Article 12). In other words, you need to build in logging from the start – it’s not optional. The logs should be detailed enough to:
- Trace decisions and outcomes – If something goes wrong, the log should help identify where and why (think of it as a flight recorder for the AI).
- Facilitate post-market monitoring – Your monitoring system (Article 72) will rely on logs to detect issues. No logs = no meaningful monitoring.
- Capture relevant data – For some systems, the law spells out additional details to log (like timestamp of each use, data checked, who verified the results).
Article 12 is short but potent. This isn’t just “keep some logs because it’s good practice.” It effectively means if you can’t reconstruct what happened in your AI’s operation, you can’t defend your system’s position in an audit or investigation. Engineering teams should treat logging as part of the model’s design: decide what events are critical (inputs? outputs? decisions? model version used?), define a schema, and ensure logs are stored securely and retained as long as required.
One practical tip: the logs required here feed directly into both incident response and monitoring. So design your logging with those use cases in mind (e.g. log the model version and configuration for each prediction, so later you can pinpoint which version was running when an incident occurred).
3) Post-market monitoring: a plan + continuous system (Article 72)
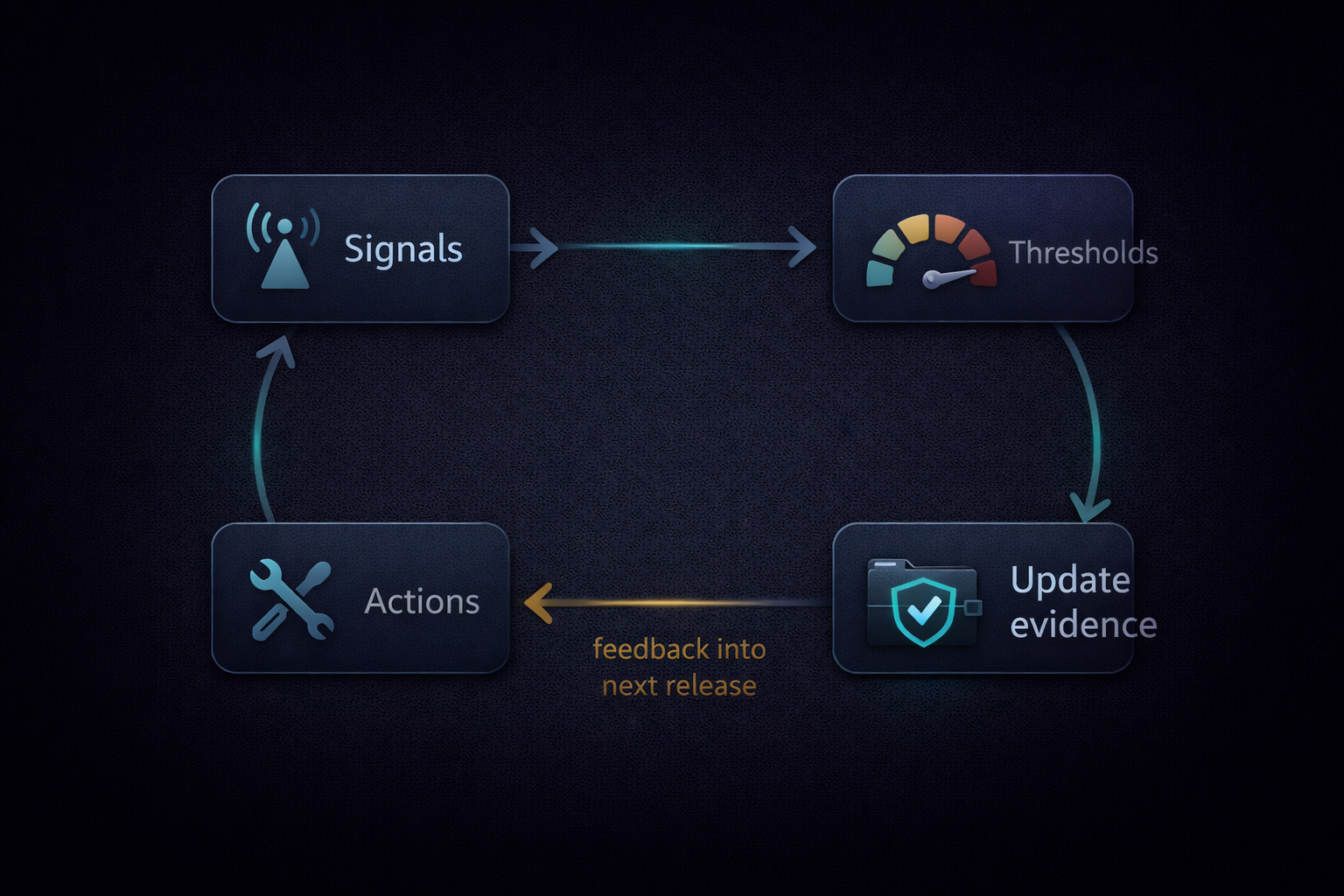
Article 72 requires providers of high-risk AI systems to implement a post-market monitoring system and have a post-market monitoring plan to guide it. Think of this as setting up an ongoing process to watch your AI in the wild and catch problems early.
A few details matter for engineering teams:
- The monitoring plan must be documented as part of your technical documentation (see Article 72 and Annex IV). That means by the time you go to market, you need a written plan for how you will monitor the AI, what data you’ll collect, and how you’ll evaluate performance and risks over time.
- The European Commission is tasked with providing a template and required elements for this plan by 2 February 2026 (Article 72(3); see Article 72). Expect a standardized format for what your monitoring plan should include (likely metrics to track, frequency of checks, and processes for handling incidents).
What does post-market monitoring look like in practice? It means you can’t just “set and forget” your model after deployment. You need to actively collect data on how it’s performing – accuracy, drift, error rates, potentially bias metrics, uptime, etc. – and also capture any incidents or near-misses. If performance degrades or new risks emerge (say, the data input distribution shifts), you’re expected to notice and do something (retrain, update the model, or even pull the model from service in extreme cases).
One way to think of it: Model monitoring is like CI/CD for risk and performance. Just as you wouldn’t deploy software without monitoring uptime and errors, the AI Act pushes you not to deploy AI without monitoring its real-world behavior and impact.
Bonus: serious incident reporting (Article 73)
Post-market monitoring feeds into another obligation: serious incident reporting. Under Article 73, providers of high-risk AI systems must be able to detect serious incidents and report them to authorities.
A “serious incident” basically means something went really wrong – e.g. the AI caused someone harm or a major near-miss. The law sets timelines for reporting, including accelerated timelines in some cases. The idea is to give regulators a heads-up on emerging risks.
For engineering teams, this is an extension of incident response. You’ll need to define what constitutes a serious incident for your system (some of this is defined in the law, but you should operationalize it) and have the mechanisms to: (a) detect that it occurred (likely via your logs and monitoring signals), and (b) have a process to investigate and report on it quickly. It’s another reason why logging and version traceability are so important – if you can’t connect an incident to a specific model version and situation, you’ll have a hard time reporting the “causal link” as the law requires.
What this means in practice (start-ups, SMEs, and enterprises)
If you’re a new company (start-up / SME)
Your advantage: you can design evidence into your delivery pipeline from day one. You’re not stuck with legacy systems or habits. And you’ll need that advantage, because compliance is a big ask for a small team.
The Act includes measures intended to support SMEs and start-ups, including regulatory sandboxes (Article 57) and support measures (Article 62) in the official text (ai-act-eurlex). In short, regulators recognise this can be hard for smaller teams and include mechanisms to reduce friction.
Founder playbook
- Pick a compliance-friendly beachhead. If you’re a founder, consider targeting a domain where evidence is already valued (healthcare, finance, public sector). Compliance can become a competitive advantage if you bake it in early.
- Treat evidence as part of the product. Shift your mindset from “we deliver a model or service” to “we deliver a model with an assurance packet.” When selling to enterprise or government, being able to hand over an Assurance Pack (see below) with all the documentation and logs can compress procurement and due diligence. It answers questions like: “What is it for and not for?”, “How was it evaluated?”, “What are the known risks and mitigations?”, and “How will you detect and handle issues?”
- Leverage sandboxes and resources. If a regulatory sandbox is available in your country, use it to pressure-test your evidence and monitoring approach. Any outputs can go into your assurance package — but validate the sandbox terms with counsel and the competent authority.
Even if your AI system is currently minimal risk, consider documenting it and monitoring it as if you had obligations. It’s easier to start with good habits than to retrofit them. Plus, enterprise customers are increasingly asking for evidence (e.g. model cards, test results, risk assessments) even for non-high-risk AI. Be ahead of the curve.
If you’re an existing organization (enterprise)
You likely have some governance structure (responsible AI committees, model documentation, etc.). The typical failure mode is fragmentation and drift:
- The Confluence wiki says one thing about the model, the production code says another.
- You have a model card that was made at launch, but the model has been updated 5 times since then.
- Risk assessments were done in a workshop, but the mitigations were never implemented or tracked.
- Different teams use different tools, and evidence is all over the place (or lost when people leave).
The AI Act’s evidence requirements essentially force alignment and single source of truth. For example, you can’t let the model drift away from its documentation – by law that documentation must be kept in sync with the current system version (see Annex IV). This is as much an organizational challenge as a technical one.
Fastest win for an enterprise: Stop treating documentation and compliance as a separate, downstream process. Integrate it into your ML workflow. For instance, require that every model that goes to production has an “assurance package” generated (even if lightweight at first) that includes all key documentation and evidence artifacts, and store it versioned in a central repository. This way, if someone asks “what changed between last version and this?”, you not only have a git diff of the code, but a diff of the assurance package (data, metrics, documentation updates, risk logs, etc.).
Also, start mapping existing tools to these needs. Maybe your experiment tracking can output evaluation reports, your DataOps can provide data provenance, etc. You don’t necessarily need one giant new system; you can script pulling pieces together. The point is to bundle and version it.
Legacy systems
What about AI systems you already have in the field? Transitional rules and what counts as a material change matter — treat it as a governance decision and check the official text and the Commission timeline (ai-act-eurlex, timeline).
A pragmatic approach: start generating evidence packs for new releases now, and then backfill legacy systems based on priority. Identify which existing AI systems would be considered high-risk (an internal audit can map your systems to Annex III categories). For the most critical ones, it’s worth doing a post hoc documentation and risk assessment exercise to have something on file. For others, plan an update and treat that update as the point where you bring it into compliance (i.e. use the update process to generate the necessary documentation and monitoring).
The key is: don’t assume “old = exempt.” Check the rules and document your rationale for how you handle legacy systems and updates.
The Assurance Pack idea: operationalizing Annex IV + Articles 12 & 72
At Ormedian, we keep coming back to one principle:
Evidence must be coupled to the version you deploy.
This principle flows directly from the Act’s evidence obligations: technical documentation (Article 11 and Annex IV), record-keeping (Article 12), and post-market monitoring (Article 72). You can’t satisfy those by doing a big Word document at launch and forgetting about it. It’s a continuous process.
So, the Assurance Pack is our pragmatic response: make the evidence package a versioned artefact just like your code or model.
Imagine for each AI release, alongside your model artifact and API, you produce a folder (and a downloadable bundle) that contains all the key evidence for that version. That’s an Assurance Pack. It would include things like:
- The intended use and limitations of the AI (what you’d put in Section 1 of Annex IV).
- The architecture and integration description.
- Data sheet: info on training data, when the data was collected, any updates.
- Evaluation results: metrics, validation reports, bias analyses for this version.
- Change log: how this version differs from the last (e.g. “added 10k more training samples from X, fixed bug in preprocessing Y, improved accuracy by 2% on minority class”).
- Risk assessment: an updated risk log or checklist (e.g. “still residual risk Z remains, but acceptable with mitigation Q”).
- Logging specification: what events the system logs, and where logs are kept.
- Post-market monitoring plan: what we’re tracking in production for this version, any new signals or thresholds added.
- Approvals: who reviewed and approved this release for compliance (e.g. the responsible AI lead signs off).
All of the above corresponds to Annex IV or related obligations. By packaging it, you ensure it travels with the software.
What an Assurance Pack looks like (example)
Here’s a conceptual structure of an Assurance Pack:
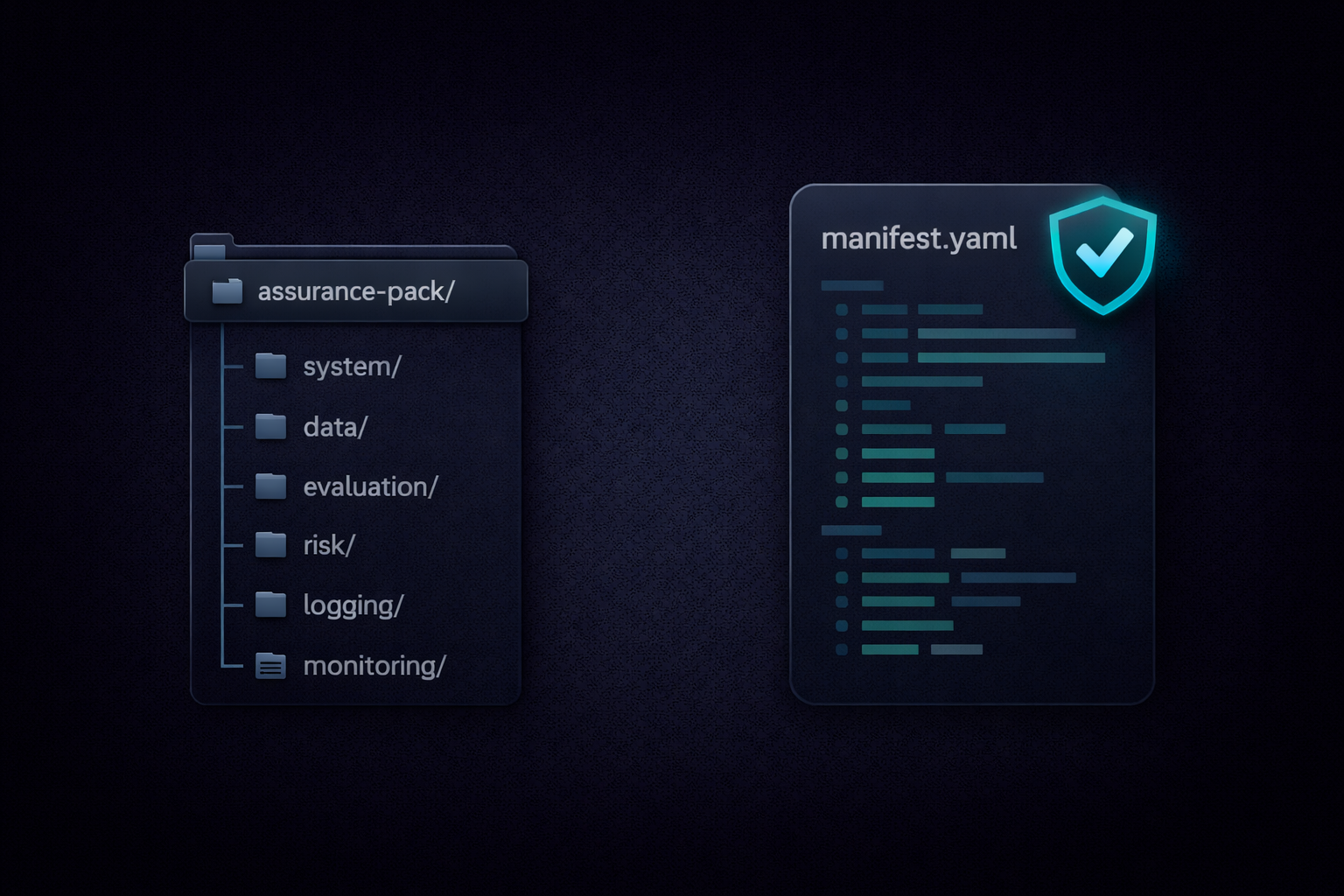
assurance-pack/
├── manifest.yaml
├── system/
│ ├── intended_use.md
│ ├── system_overview.md
│ ├── architecture.md
│ ├── integration.md
│ ├── limitations.md
│ └── change_log.md
├── data/
│ ├── provenance.md
│ ├── preprocessing.md
│ └── labeling.md
├── evaluation/
│ ├── eval_plan.md
│ ├── metrics_summary.json
│ ├── slice_results.csv
│ └── robustness_tests.md
├── test_logs/
│ └── ... (raw logs or links to test run outputs)
├── risk/
│ ├── risk_assessment.md
│ ├── risk_controls.md
│ └── human_oversight.md
├── logging/
│ ├── logging_spec.md
│ ├── event_schema.json
│ └── retention_policy.md
├── monitoring/
│ ├── post_market_monitoring_plan.md
│ ├── signals_and_thresholds.yaml
│ ├── incident_playbook.md
│ └── escalation_contacts.md
├── governance/
│ ├── roles_and_accountability.md
│ └── approvals.md
└── attestations/
├── hashes.txt
└── signature.sigAnd a minimal manifest.yaml inside might contain metadata and pointers:
pack_version: 0.1
system:
name: "ExampleAI"
release_version: "1.4.0"
previous_release: "1.3.2"
provider: "YourCompany"
deployment_context: ["EU"]
classification:
high_risk_candidate: true
rationale: "Annex III use-case (employment) – likely high-risk"
evidence:
technical_documentation:
annex_iv_mapping: "system/system_overview.md"
record_keeping:
article_12_logging_spec: "logging/logging_spec.md"
post_market_monitoring:
article_72_plan: "monitoring/post_market_monitoring_plan.md"
quality_gates:
min_accuracy: 0.92
regression_tolerance: 0.01
approvals:
- role: "Responsible AI Lead"
name: "Dr. Jane Doe"
date: "2026-01-24"It’s intentionally not fancy. The wow factor isn’t the YAML or the folder tree – it’s the process change: making this evidence packet a required output of every release and treating it with the same importance as the model artifact or source code. That enables automation (e.g. you can diff two manifests to see what changed, or automatically check if certain fields are present or within policy thresholds).
How it fits into delivery (conceptual)
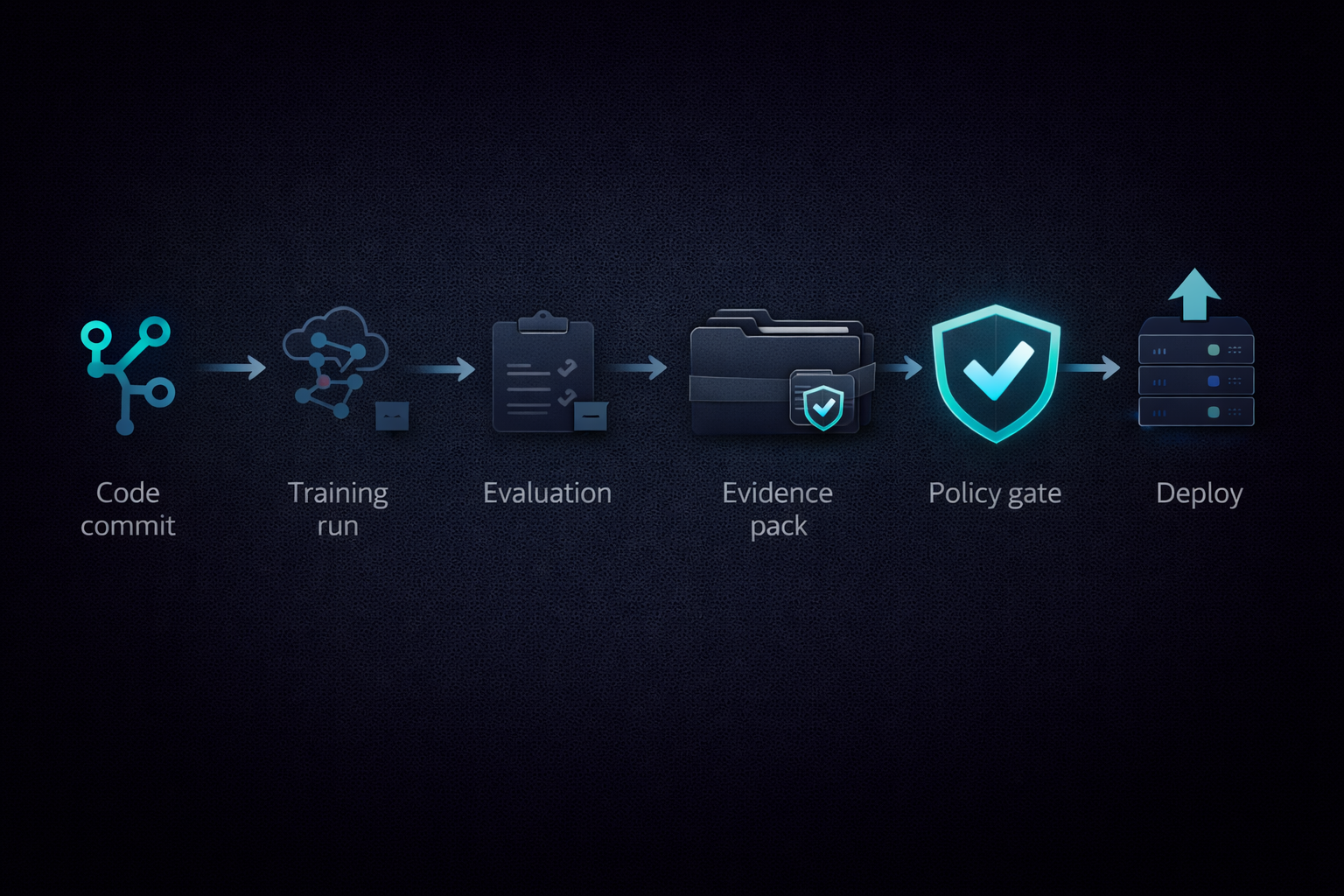
How do you actually produce these without killing your team’s velocity? The trick is to automate as much as possible and make it part of CI/CD:
- Develop & train as usual (not much change here).
- Evaluate as usual – but ensure your evaluation spits out artifacts (metrics, graphs, maybe a PDF report or JSON summary).
- Assemble the pack: Have a script or CI job that gathers all the pieces (the model card from your training pipeline, the evaluation metrics, the data schema, etc.) and puts them in the right folder structure. Some pieces might be written by humans (e.g. “limitations.md” might be manually maintained), but many can be generated or templated.
- Validate the pack: Just like you wouldn’t deploy if tests fail, set a rule that you don’t deploy if the assurance pack is incomplete. For example, check that
metrics_summary.jsonshows performance above your required threshold, thatrisk_assessment.mdhas been updated for this version (maybe require a specific commit message or checklist). - Publish/store the pack: Store it in artifact storage or attach it to the release in your repository. Treat it as deliverable. If an auditor or client wants it later, it should be readily accessible.
- Deploy the AI system (if all gates pass, including evidence checks).
If you’ve heard of software bills of materials (SBOM) in cybersecurity, this is a similar concept – an evidence BOM for AI. It ensures that whenever your AI ships, the evidence of its trustworthiness ships with it.
What auditors and procurement actually ask (and how packs answer)
When facing an audit or customer security review, you’ll often get a spreadsheet or questionnaire. Assurance Packs, if done well, let you answer many questions by just handing them the pack (or extracting the relevant parts quickly).
Typical questions and where the pack addresses them:
- “What is this AI system for, and what are its limitations?” – Check intended_use.md and limitations.md in the pack. This should clearly state the purpose, scope, and contexts where the AI should (or should not) be used. It’s basically your Annex IV Section 1(a) & (c) info.
- “Show me how you evaluated it for that use.” – The pack’s evaluation/ folder should have an evaluation plan (eval_plan.md) and results (metrics, slices, robustness tests). This demonstrates that you tested the system on relevant data and know its performance (see Annex IV).
- “What are the risks and how do you mitigate them?” – The risk/ section of the pack holds your risk assessment and any mitigations (like human oversight measures, fail-safes, bias mitigations). This aligns with the Act’s risk management expectations (Article 9 and Annex IV sections on risk). If you identified, say, a risk of bias against a subgroup, you’d note it and perhaps point to a control (maybe a periodic bias audit in monitoring).
- “How do you detect and handle issues in production?” – The monitoring/ folder includes the post-market monitoring plan (signals, thresholds, actions) and an incident response playbook. This shows that you’re not just throwing the model over the wall – you have a process to watch it and respond.
- “Can you trace decisions if something goes wrong?” – The logging/ folder holds the logging specification and schema, which shows you’ve built traceability (and you can even provide sample log data if appropriate, or show an incident report tracing through logs).
- “Who takes responsibility?” – The governance/roles_and_accountability.md and approvals.md should list the accountable roles (e.g. who the provider is, who the product owner is, etc.) and who signed off on the release. This aligns with the Act’s emphasis on defined responsibilities and quality management (Article 17 even requires a Quality Management System with assigned responsibilities).
By structuring evidence this way, you turn a potential 2-week back-and-forth Q&A into a quick lookup. It also impresses auditors: it shows maturity if you can immediately pull up the exact document or data they ask for, versioned for the release in question. No scrambling through folders named “final_final_really.pdf” – you have it organized.
Common failure modes (and how to design around them)
Through working on these issues, we’ve seen patterns of how evidence efforts can falter. Here are some common pitfalls and how a release-focused approach addresses them:

-
Stale documentation: The classic “doc written once and never updated.” Six months later, it’s out of sync with the actual system.
Solution: Make documentation part of the release checklist. If the pack for version 1.4.0 isn’t present or is missing sections, the release doesn’t get tagged. By tying docs to each version, you force updates as part of the dev process, not as an afterthought. -
Metrics without context: Teams often throw a few performance numbers into a report. But without context (what was the test set? what slices or edge cases were checked? what’s the target performance?), numbers mean little.
Solution: Require an evaluation plan and sliced results in the pack. This means before training, you define how you’ll validate (which forces thinking about relevant scenarios). And after training, you include not just “overall accuracy 94%” but, for example, “accuracy per subgroup, worst-case = 88% on subgroup X” plus any stress tests. That gives a fuller picture. -
Monitoring that doesn’t match risks: It’s common to see a monitoring dashboard that tracks CPU usage and maybe overall prediction count – but nothing about whether the model is drifting or making more errors.
Solution: In the monitoring plan, explicitly tie metrics to risks. If your risk assessment says “may have lower accuracy on older patients,” then your monitoring should include a check on performance by age (if you can get that data) or at least a proxy. If bias is a risk, include some bias indicators. Essentially, close the loop: each major risk should have a corresponding monitoring signal or periodic check. -
No traceability across versions: When something goes wrong, the team isn’t sure which model version was running or what data was used. This is a nightmare for accountability (and regulators won’t accept “we’re not sure which model was live”).
Solution: Always log the model version (and ideally a unique identifier for the model build) on every prediction or decision. And in your pack’s manifest, maybe include a hash of the model file and code used. That way, you can always match a log entry to the exact version and evidence pack. Also, store packs in an immutable store (even just a versioned S3 bucket) so you can pull up the exact docs that correspond to a version. -
No incident playbook: When an issue happens, it’s chaos – people aren’t sure who leads the investigation, or how to decide if something is serious enough to report to regulators.
Solution: Include an incident response plan in the pack (and of course, internally train on it). It should say: if X type of incident occurs, here’s how to assess it, here’s who convenes to decide next steps, here’s how to file a report under Article 73 if needed. This way, every release reminds the team “we have a process if something goes wrong.” It’s much easier to follow a plan than to ad-lib under pressure.
A starter outline for an Article 72 post-market monitoring plan
The Commission is expected to adopt a template for the post-market monitoring plan by 2 February 2026 (Article 72(3); see Article 72). But you don’t have to (and shouldn’t) wait for that to start planning. Here’s a practical outline you can start filling in now, which should align well with Article 72’s intent:
1) Scope and context: Define which system this plan covers (name, version, etc.), its intended use, and deployment context. Note who the provider is and who the deployers are (if different). Essentially, set the scene: “This plan monitors System X version Y in Z environment for intended purpose P.”
2) Risks and assumptions: Summarize the key risks from your risk assessment. “We are particularly watching for performance degradation on dataset drift, or an uptick in false positives causing potential harm, etc.” List hypotheses like “if metric M goes above threshold T, it could indicate risk R is materializing.”
3) Signals to monitor: For each risk or important aspect, what metrics or signals will you track? For example: input data drift (monitor distribution of inputs over time), output quality (monitor error rates against a validation dataset or human feedback), bias (monitor outcomes by demographic if available), system uptime, etc. Also external signals like user complaints or support tickets could be included.
4) Thresholds and triggers: Decide what levels of those signals warrant action. Maybe you set a warning threshold and an incident threshold. E.g. “If weekly accuracy drops by more than 5 points, data science team investigates within 1 week. If drops by 10 points or more, halt model and failover to manual process.” This is essentially your SLA for model performance and risk.
5) Logging and traceability link: State how you will use logs in monitoring. “All predictions are logged with timestamp and key attributes; monitoring jobs run daily to aggregate these logs and check for anomalies. In case of incident, logs will be analyzed to trace root cause.” (This connects to the Article 12 obligation – your plan should reference that you have the data to support it.)
6) Review cadence: How often will you formally review the monitoring data and overall system performance? Perhaps you have a monthly governance review where you look at trends, and a yearly full audit. Mention that. The Act will expect you to continuously update the technical documentation with new findings, so tie that in: “Results of monitoring will feed into periodic updates of technical documentation and risk assessment.”
7) Continuous improvement: Explain how you will update the system or process when issues are found. For instance, “If drift is detected, we will retrain the model on latest data within X weeks,” or “If new risks are identified, we will update the risk log and implement mitigation.” This shows you have a learning loop, not just monitoring in name only.
8) Reporting workflow: Outline how internal escalation works. “On detecting a serious incident, the on-call ML engineer notifies the AI Risk Officer; a root cause analysis is done; if criteria for Article 73 reporting are met, we will file a report to authorities within the required timeline.” Basically, tie your plan into the legal reporting duty so it’s clear you won’t drop the ball.
Documenting this now not only prepares you for compliance, it actually helps your team. It’s much easier to sleep at night knowing you have a sensor on the system and a plan for what to do if it blips.
“Isn’t this something platforms can just add?”
You might wonder: won’t the AWS/GCP/Azure/ModelOps platforms of the world just solve this with a new feature? They will certainly help on parts – for example, logging and monitoring tools are out there, and they can add compliance checklists. But a key differentiator here is portability and version-coupling of evidence.
Many platform solutions focus on dashboards or documents in situ. The Assurance Pack concept is about a portable bundle that you can hand over to an auditor or customer, or move to another platform, and it still makes sense. It’s decoupled from any specific tooling UI. It’s also verifiable in the sense that you can sign it, hash it, and show it wasn’t tampered with.
Think of the security world: cloud providers offer great security centers, but companies still produce their own artifacts for audits (architecture diagrams, access reviews, etc.) that are portable. Similarly, you as AI providers will want a portable evidence artefact that you own and control, which can be shared externally as needed (under NDA or via secure channels likely).
Platform vendors can assist by generating pieces of the evidence (like auto-generating parts of the technical documentation, or providing one-click model cards), and they might even allow exporting a “compliance bundle”. But until that’s common, rolling your own lightweight process as described can give you a head start (and more control).
What you should do this quarter
A call to action for engineering and product teams:
-
Determine if you’re in scope (and at what level). Map your AI use-cases to the Act’s categories. Are you possibly high-risk (see Article 6)? If yes, is it an Annex I regulated-product scenario or an Annex III use-case? Use the definitions in Article 3 to clarify your role (provider/deployer/etc.). If you’re not high-risk, great – but remember that enterprise customers might still ask for “AI governance” evidence, so it’s worth adopting a light version of these practices anyway.
-
Start treating evidence as a deliverable. Kick off an initiative to define what an “Assurance Pack” would be for your main AI system. Pick a recent release and try to compile the key items. This will highlight gaps (e.g. “oh, we never actually wrote down our intended use and limitations clearly”). It’s fine if it’s messy at first. Create a template and iterate.
-
Build the monitoring plan now. Don’t wait until 2026 when the official template drops. Begin drafting a post-market monitoring plan for your system using the outline above. Even if it’s rough, it will surface questions (What should we monitor? Can we get that data? Who would be on the hook if X happens?) that you’re better off answering sooner rather than later. By the time the Commission’s template arrives, you’ll have a version to align with it, rather than starting from scratch under time pressure.
By focusing on these steps, you’ll not only de-risk compliance, but you’ll likely improve your AI practice overall. It’s the whole “sunlight is the best disinfectant” idea – making yourself document and monitor forces you to build better, more reliable AI.
How Ormedian helps (mapping to the evidence triangle)
At Ormedian, we’re building tools around one idea: ship AI you can defend. In practice, that means helping teams generate and manage the kind of evidence we’ve discussed – without losing agility.
Here’s how it lines up with the evidence triangle:
-
Evidence Packs (Technical documentation) – Ormedian helps you generate structured evidence packs aligned with Annex IV, every time you release. Instead of scrambling to write docs, you get a lot of it auto-assembled from your pipeline (and you can plug in your own content where needed). The pack stays tied to the model version. It’s like having a continuously updated technical file, versioned in lockstep with your model.
-
Monitoring by default (Post-market) – We provide out-of-the-box monitoring templates (grounded in Article 72) that you can customize. You define your key metrics and risks, and our tool hooks into your inference pipeline or product to start tracking them. The monitoring plan and live dashboard become part of your assurance package. If drift or anomalies are detected, it not only alerts you, but also logs the event for your records. Think of it as turning your post-market monitoring plan into a living part of your CI/CD – so you’re always ready to show regulators how you keep an eye on things.
-
Provenance & traceability (Logging) – We integrate with your infrastructure to capture the necessary logs (Article 12) and link them to each prediction or decision. We also help maintain a lineage: which data and model went into this version, and where did it come from. Our Assurance Pack includes an attestation section (hashes, signatures) to prove integrity – so you can show that the model you evaluated is exactly the model running in production and exactly the model you have documentation for. This is crucial for trust. It’s a bit like having an aircraft maintenance log for your AI – everything recorded and signed off.
In short, Ormedian is aiming to be the toolset that makes all this feasible without a giant internal compliance team. We’re focusing on early adopters across industries – whether you’re building AI for HR, health, industrial automation, whatever. The EU AI Act’s principles apply universally, and we think the Assurance Pack approach can too.
Join the waitlist
Interested in deploying AI with confidence? We’re working closely with early partners to refine the Assurance Pack workflow. If you want early access or to collaborate on defining “what good evidence looks like” in your industry, join the waitlist →. We’d love to learn about your use-case and help you stay ahead of these requirements.
Primary sources
- Regulation (EU) 2024/1689 (EUR-Lex, official text)
- Commission Service Desk timeline
- Article 3 — Definitions
- Article 4 — AI literacy
- Article 5 — Prohibited practices
- Article 6 — High-risk classification
- Article 11 — Technical documentation
- Article 12 — Record-keeping
- Article 50 — Transparency obligations
- Article 72 — Post-market monitoring
- Article 73 — Serious incident reporting
- Annex I — Regulated products
- Annex III — High-risk use-cases
- Annex IV — Technical documentation content
Further reading
Join the waitlist
Get early access to Ormedian tools for assurance packs, monitoring, and provenance.
Join waitlist